




How a five-symbol alphabet exposes three “independent” clusters as a single campaign
The Missing Dimension
When analyzing bulk-registered domains for threat intelligence, clusters are commonly identified by two complementary methods: infrastructure signals (name server configuration, registrar, hosting) and naming properties (structural patterns, vocabulary, character composition). Both approaches are well established. Infrastructure signals work because provisioning large numbers of domains is invariably done through automation, and automation tools leave consistent fingerprints. Name servers, registrar choices, and tool-level configurations tend to be uniform across everything a given tool registers, making them reliable grouping criteria. Naming analysis has attracted considerable research attention. Character n-grams, entropy metrics, word-list membership, and domain length distributions are all routinely applied to characterize and separate domain clusters.
What receives far less attention is the numeric component of the domain name when one is present. When a domain name contains digits, for example, chat-21004430.com, connect-02043120.com, the number is typically acknowledged at a surface level: how many digits it contains, whether they are leading or trailing, the digit-to-character ratio, perhaps a rough range check. Deeper statistical analysis of the numeric component, including its digit alphabet, its distributional properties, the encoding choices embedded in its generator, is largely absent from published threat analysis.
That gap is worth closing. The numeric component is not just noise appended to make domains unique. It encodes decisions baked into the generator at design time, decisions that stay constant regardless of which infrastructure cluster the domain lands on, which registrar was used, or when registration happened. That invariance, if detectable, makes the numeric component a particularly reliable provenance indicator for the cluster merge problem: determining whether multiple distinct clusters are actually produced by the same generator.
The case we walk through here involves three clusters, each detected independently by our system, and each appearing to be a self-contained campaign. Our goal is to show that despite appearing unrelated, all three were produced by the same generator. And we’ll do it through the numbers. Infrastructure analysis does its job. It correctly identifies three separate clusters. Naming analysis finds strong but not conclusive overlap. It is the numeric component that settles the question, and it does so through a single observation.
What’s in a Number?
Before getting into the case, it helps to highlight critical distinction. All numbers are equal, but not all numbers in domain names are made equal.
When a domain generation system produces a digit string, it can take two fundamentally different approaches.
Character-level generation treats digits as characters with no numeric meaning. The generator samples from a character alphabet that happens to include some or all of 0–9, the same way it might sample from a–z. The resulting string 31004430 is not the number 31 million. It is a sequence of eight characters, each independently drawn. Digit frequency, range, and distributional properties carry no special information beyond what any character-frequency analysis would reveal. Much of what gets labeled “random-looking” domain number analysis in practice is implicitly assuming this model.
Numeric generation treats the digit string as the representation of an actual number, whether decimal, fixed-width, or expressed in some other base. The generator is working in a numeric space: sampling integers, incrementing a counter, hashing an input, or encoding an index. The digit string you see in the domain name is simply that number rendered in a particular format. And this matters a lot. The choice of number space, how it is sampled, zero-padding conventions, and the base used all leave statistical traces that are specific to that generator and show consistently across every domain it produces.
The two approaches aren’t always easy to tell apart at a glance. A practical test is whether the digit string shows properties that only make sense at the numeric level: a restricted digit alphabet, a leading‑digit distribution that breaks Benford’s Law, uniform coverage of a bounded range, or consistent fixed‑width formatting that points to a specific number space. When those show up, numeric analysis is the right tool to reach for.
There’s a subtlety worth calling out, though. In the case analyzed below, with fixed width strings where all eight positions are filled and digits are drawn uniformly, the two approaches produce output that looks exactly the same from the outside. A generator that samples a random integer from a base‑5 space and formats it as an eight‑digit string is indistinguishable from one that just rolls each digit independently from {0, 1, 2, 3, 4}. Same alphabet. Same length. Same flat distribution.
So, the data can’t tell us how the generator works internally. What it can tell us is that the generator is constrained to a fixed‑width quinary space and samples it uniformly—and that constraint is unusual enough to be diagnostic regardless of implementation.
In the cluster we’re looking at, that constraint is hard to miss. And it’s exactly what turns the link between three separate infrastructure clusters into something you can actually prove, not just suspect.
Three Clusters, One Pattern
Here’s what detection system hands us: three separate clusters, each containing a few thousand .com domains. Treated in isolation, each looks like a coherent cluster. The question is whether they’re related.
A first look at the domains themselves makes you lean toward yes but isn’t sufficient for attribution.
| Cluster 1 | Cluster 2 | Cluster 3 |
|---|---|---|
| engage-21111223.com | sales-41403444.com | connect-13333210.com |
| sales-43420231.com | link-21123113.com | join-13123303.com |
| network-44300312.com | join-20444321.com | network-03331432.com |
| join-03140312.com | network-41220410.com | link-02331130.com |
| network-00022401.com | engage-33241442.com | interact-34332404.com |
| chat-01033432.com | join-14244311.com | interact-23410021.com |
| chat-22431310.com | link-03440423.com | connect-10142201.com |
| connect-42304321.com | join-33343412.com | engage-31401033.com |
The resemblance is obvious at a glance: the same composition structure, use of overlapping vocabulary, and suspiciously similar-looking numbers. But resemblance isn’t attribution. Any two bulk-registration campaigns targeting the same brand might independently land on {word}-{number}.com. The words connect, join, and link are generic enough that separate actors could pick them without coordination. And those eight-digit numbers could plausibly be random noise added to ensure uniqueness.
So, we have three clusters, clearly similar domains, and reasonable grounds for suspicion. How do you get from suspicion to something you can actually stand behind?
Even at the structural level, the three clusters look suspicious right away. Every single domain across all three follows the same template: {word}-{number}.com. No variation, no outliers across nearly 7,000 domains. The word component is drawn from a fixed vocabulary of nine terms:
chat, connect, engage, interact, join, link, meet, network, sales
All nine words show up in all three clusters at nearly identical rates, roughly 11 percent each. That’s not what you would expect from three teams independently building communication-themed infrastructure. That’s a generator pulling uniformly from a fixed word list.
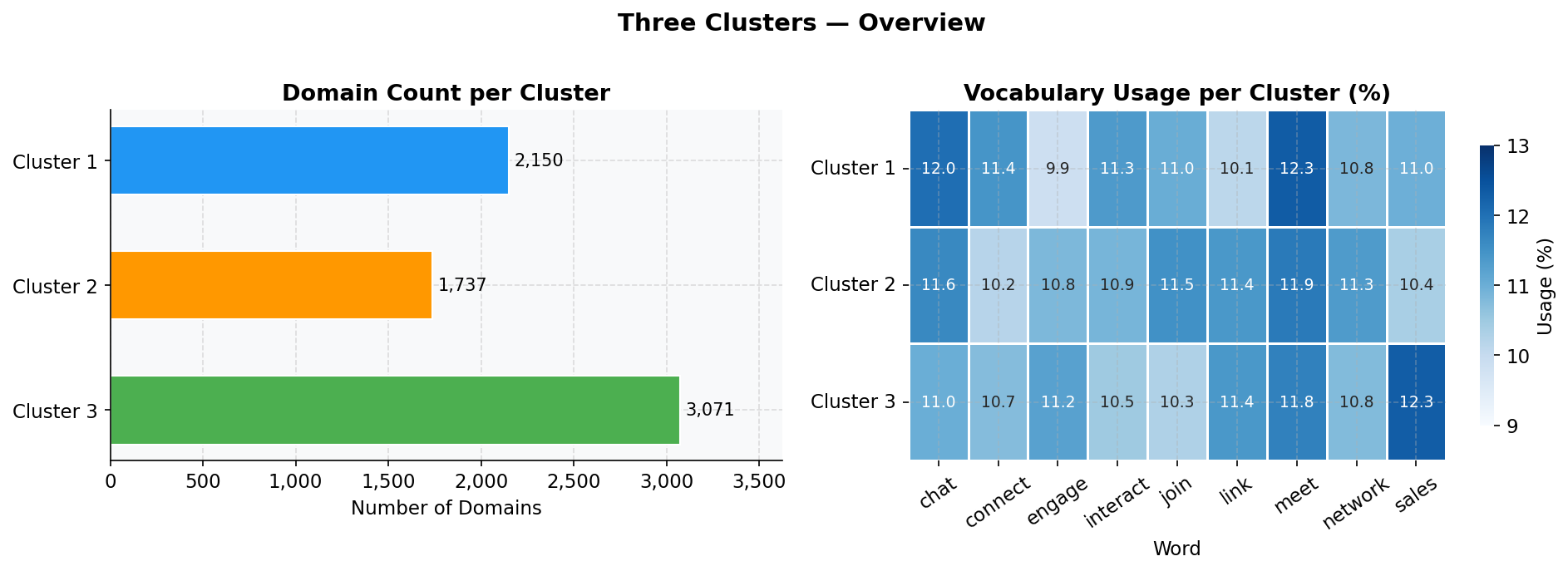
Figure 1. Left: Domain count per cluster. Right: Word usage proportion per cluster. All nine words appear in all three clusters at nearly identical rates (~11 percent each), consistent with uniform random selection from a fixed vocabulary.
Vocabulary overlap is useful, but it doesn’t close the case on its own. Generic terms like connect or link are plausible independent choices for anyone building a communications-themed persona. What turns the coincidence into provenance is the numeric component.
The Number That Shouldn’t Look Like This
Each domain carries an eight-character numeric suffix: chat-21004430.com, connect-02043120.com, meet-30101420.com. These strings look random. But before accepting that, it’s worth asking a very simple question: which digits are actually used?
Across 6,958 domains and 55,664 individual digit positions, the answer is unambiguous.
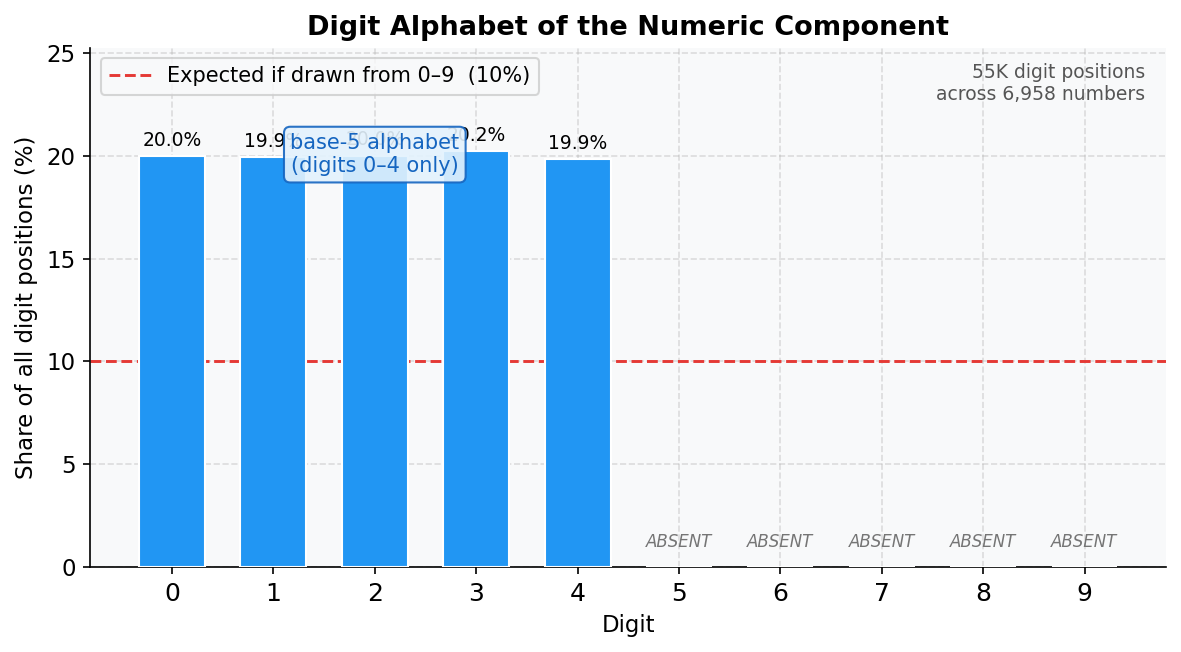
Figure 2. Frequency of each digit (0–9) across all 55,664 digit positions in the numeric component. Digits 5 through 9 are completely absent. The expected frequency if digits were drawn uniformly from 0–9 would be approximately 10 percent each (dashed line).
The absence of five digits isn’t just a frequency curiosity. It carves the entire decimal number line into isolated islands. Read naively as decimal integers, the domain numbers can never fall in the ranges such as 5,000,000–9,999,999, or 15,000,000–19,999,999, or 25,000,000–29,999,999, and so on. Every range containing a forbidden digit is structurally unreachable. Once converted to their true integer values (treating the strings as base-5 notation), those gaps disappear, and the underlying uniform distribution becomes immediately visible.
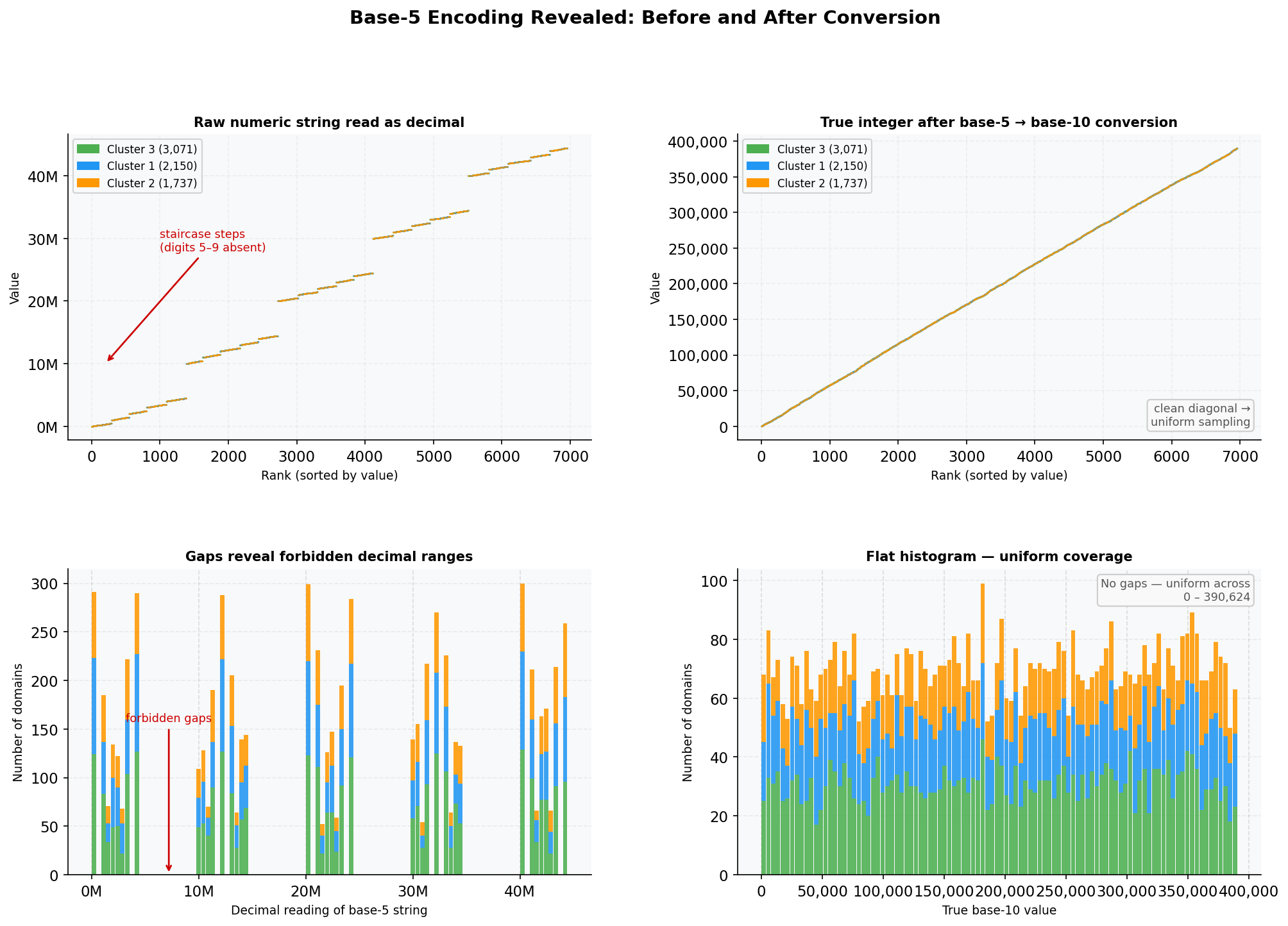
Figure 3. Top row: Sorted scatter of all domain numbers—as decimal readings (left) and as true base-10 integers after base-5 conversion (right). Bottom row: Stacked histograms of the same data. The left column exposes the staircase structure imposed by the absent digits 5–9; the right column shows the uniform distribution that was always underneath.
Digits 5 through 9 do not exist anywhere in this dataset. The generator is producing numbers in base-5, the quinary number system, which uses only the symbols {0, 1, 2, 3, 4}. An eight-character base-5 string addresses a space of 5⁸ or 390,625 distinct values. The 6,958 unique numbers in this cluster represent approximately 1.8 percent coverage of that space, consistent with uniform random sampling from it.
Notably, base‑5 is an extremely uncommon choice in computer systems, which overwhelmingly favor bases aligned with powers of two (binary, octal, hexadecimal) or decimal for human interfaces.
The ~20 percent of domain numbers that begin with 0 (for example, connect-02043120.com) are not errors. They are fixed-width representations of base-5 values smaller than 10000000 base-5, zero-padded to maintain consistent domain name length. This is a formatting decision embedded in the generator.
The Statistical Fingerprint
The digit restriction alone is enough, but there’s a second layer of confirmation in the distribution of the digits that do appear.
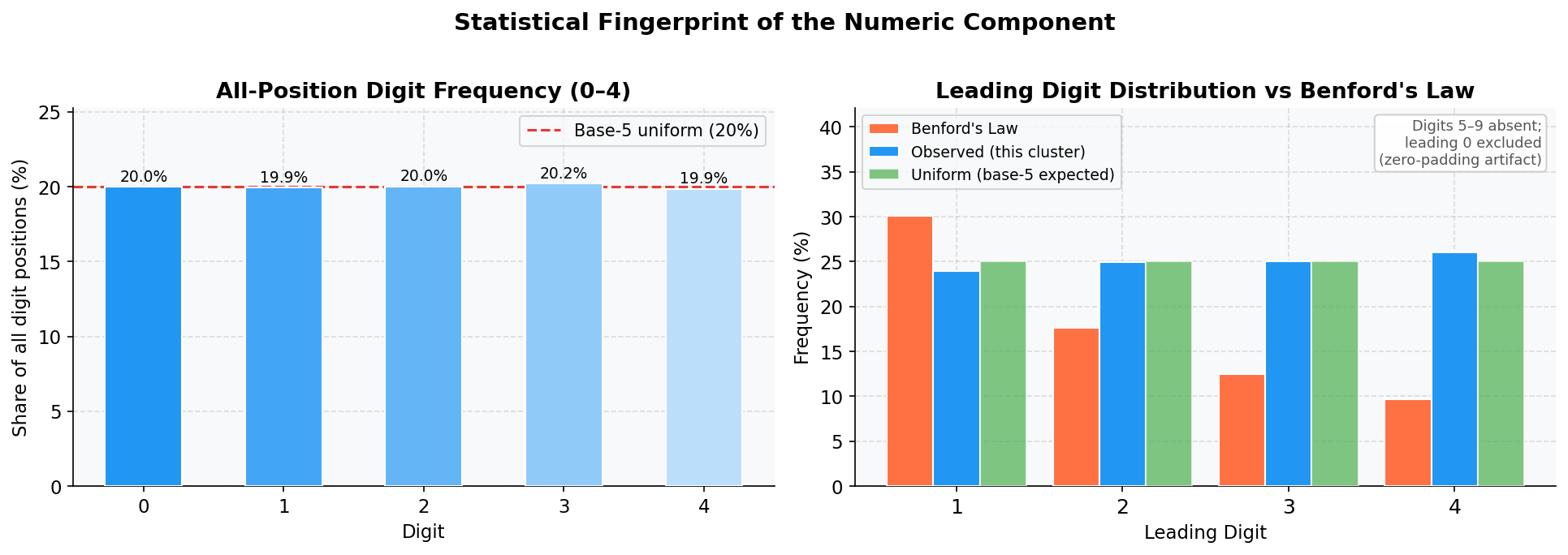
Figure 4. Left: Observed frequency of each digit (0–4) across all positions, compared to the expected uniform rate of 20 percent. Right: Leading digit distribution compared to Benford’s Law. Naturally occurring numbers follow Benford’s Law (digit 1 appears ~30 percent of the time; digit 4 only ~10 percent). These domain numbers show an approximately uniform distribution across 0–4, the fingerprint of uniform algorithmic sampling.
Numbers that occur naturally, such as counters, prices, and identifiers that humans assign, tend to follow predictable patterns. The most familiar example is Benford’s Law. In any large collection of naturally occurring numbers, digit 1 appears as the leading digit about 30 percent of the time, digit 2 about 18 percent, and so on, with higher digits becoming progressively rarer. The intuition is simple: in bounded real-world contexts, smaller numbers occur more frequently than larger ones.
These domain numbers don’t follow that pattern at all. Digits 1 through 4 each appear as the leading digit in 19–21 percent of cases, producing a flat, uniform distribution with no preference for any particular digit. That’s the distribution you get from uniform random sampling within a bounded numeric space, not from anything a human would generate, or any natural process would produce.
Restricted alphabet plus uniform distribution equals a generator fingerprint. Two independent actors don’t accidentally build the same one.
Simultaneous Operations Confirm Coordination
There’s one additional piece of evidence. All three clusters have their domains registered within the same narrow window, primarily November and December 2024, in large daily batches of several hundred to over 2,000 domains per day.
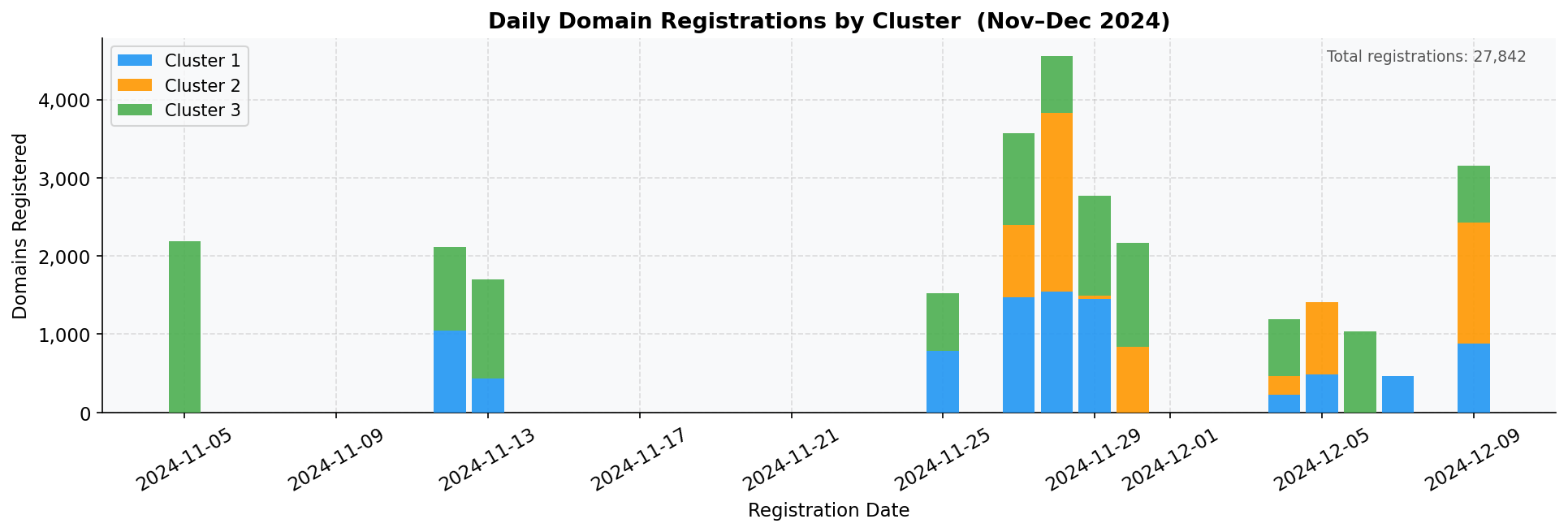
Figure 5. Daily domain registrations across all three clusters, November–December 2024. Registration activity overlaps substantially, consistent with a single operator running parallel provisioning jobs rather than three independently timed campaigns.
Campaigns do occasionally overlap in time by chance. At this point, however, the numeric evidence has already made the case, and the registration timeline just confirms it.
Numeric Analysis as a Merge Criterion
Four lines of evidence support attribution to a single generator: structural pattern, vocabulary, numeric encoding, and registration timing. But they are not equally decisive:
| Evidence | Weight | Reasoning |
|---|---|---|
| Shared structural pattern | Moderate | Common in bulk domain campaigns generally |
| Shared vocabulary (nine words) | Moderate | Generic terms; possible independent selection |
| Identical digit alphabet (base-5) | Strong | Structural generator property; not reproducible independently |
| Uniform digit distribution | Strong | Statistical generator fingerprint |
| Overlapping registration timeline | Moderate | Corroborating, not definitive |
The digit alphabet is what elevates resemblance to attribution. Pattern-based clustering groups domains by structure, and infrastructure correctly separates clusters, but neither of them tells you whether those clusters belong to one campaign. The numeric component does.
That’s the practical value here: numeric analysis characterizes the generator, not the deployment. The generator properties don’t change based on which account the domain was registered under, which registrar was used, what name servers are configured in, or when it went live. Two clusters from the same generator will share numeric properties even when every other signal points in different directions.
Conclusion
Numeric components of domain names are frequently undervalued. In practice, they are often treated as noise and either removed prior to analysis or reduced to coarse abstractions such as a binary “contains digits” flag, generic n‑gram features, or entropy scores. This case argues strongly for more careful treatment.
The choices baked into a number format, including its length, its digit alphabet, and how its values are distributed, are decisions made when the generator was built. They travel with every domain that generator ever produces, across every deployment, every registrar, and every registration batch.
Here, a generator that works in base-5, one that simply cannot produce digits 5 through 9, is what ties three separately detected clusters into a single campaign. The odds of three independent actors independently landing on the same unusual encoding are, to put it generously, not meaningful.
Amusing, perhaps. But unmistakable.
Analysis performed on a cluster of 6,958 domains, registered November–December 2024. All domain names, name server configurations, and registration dates are drawn from passive DNS and public WHOIS data.


