




Lookalike attack success does not rely on exploiting software flaws or compromised infrastructure. It plays on human tendencies to read what we expect, accept what we see and mentally autocorrect what we read.
By designing domain names that resemble common services, roles or contexts, attackers exploit how people recognize and trust familiar patterns. These attacks bypass technical controls and succeed inside the human decision-making loop. Ambiguity is not accidental. It is the design principle that allows lookalike domains to remain effective and long-lived.
This analysis builds on earlier empirical work on lookalike domains, including Infoblox’s 2023 report A Deep3r Look at Lookal1ke Attacks, which documented the scale, prevalence and technical variation of real-world campaigns. Rather than revisiting that taxonomy, this work focuses on the structural and cognitive properties that make lookalike domains effective, persistent and difficult to classify, and on what DNS data can and cannot reveal about attacker intent before overtly malicious activity occurs.
1. At a Glance
Cyberattacks are commonly described in terms of technical exploits such as vulnerabilities, malware or compromised infrastructure. Security teams invest heavily in patching, endpoint protection and network monitoring, all aimed at stopping attacks before they reach critical systems. Threat actors use lookalike domains to sidestep all of that in phishing and other campaigns. They do not need to compromise systems when they can compromise judgment.
A lookalike attack uses a domain name crafted to resemble something familiar, such as a bank, an internal company portal or a trusted vendor. In a moment of inattention, a person accepts it as legitimate and acts accordingly. The victim clicks, logs in, opens a document or initiates a download before realizing anything is wrong.
This is not a niche edge case. Attacks that rely on human interaction consistently bypass technical controls by exploiting perception and trust rather than system vulnerabilities. Phishing is the most common example, but it is not the only one. The domain name is the lure. The human is the exploit surface.
What makes lookalike attacks particularly difficult to address is their inherent ambiguity. A domain that embeds a well‑known brand name may belong to a legitimate content delivery network, a third‑party service provider or an attacker preparing a phishing campaign. At the moment of registration, and often for days or weeks afterward, these cases are indistinguishable from a user perspective. Attackers are aware of this and use it deliberately, maintaining plausible deniability for as long as possible.
Despite this ambiguity, lookalike attacks leave observable traces. DNS infrastructure, the system that resolves every domain name on the internet, records which names are being queried, how they are structured and which legitimate entities they reference. With the right analytical lens, this data reveals which targets attackers are emphasizing, how the deception is structured and who the attack is meant to influence, even before any overtly malicious activity occurs.
A domain name alone does not tell us what is malicious. It tells us what attackers want their victims to believe. That is a different, and often more useful, kind of signal.
If you take away one idea: Lookalike attacks exploit human trust, not technical weaknesses. They require a fundamentally different detection model and organizational response from malware-driven threats.
2. The Real Target
Not all malicious domains are created equal. To understand an attack and how to defend against it, it helps to start with a deceptively simple question. Does it involve a human at all?
Figure 1 illustrates a way to create two broad classes of malicious domains: system‑targeted attacks that operate without human involvement, and human‑targeted attacks that rely on perception and trust.
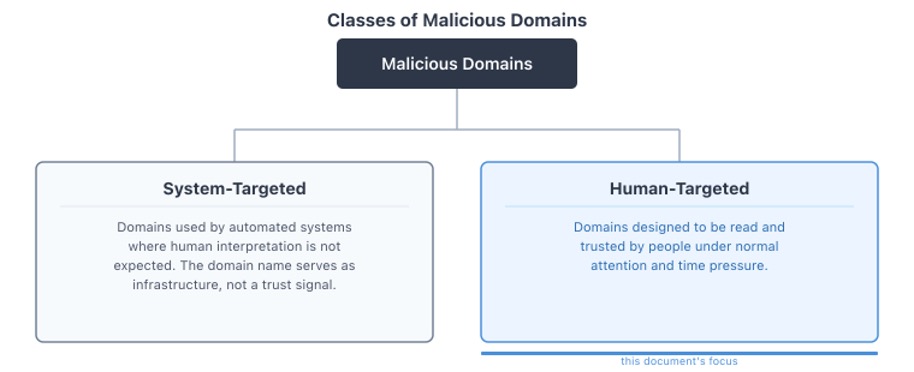
Figure 1. Classes of malicious domains: system-targeted vs. human-targeted
Attacks on Systems
Some malicious domains are never meant to be read, recognized or trusted by humans at all. They exist solely to support automated activity, such as malware command‑and‑control (C2), infrastructure coordination or large‑scale abuse. In these cases, the domain name does not need to look legitimate or meaningful. It only needs to resolve.
Domain generation algorithms (DGAs) are a well‑known example. Malware can algorithmically produce large numbers of candidate domains and attempt to resolve them until one becomes reachable, without any human involvement. Other system‑targeted attacks operate at this same layer, including search engine poisoning, DNS cache poisoning and malware infrastructure that rotates domains and IP addresses to evade disruption. In all these cases, domains serve as operational endpoints rather than signals of trust.
Detection of system‑targeted domains relies on statistical, behavioral and infrastructural properties rather than semantics, because no human reader is expected. High lexical entropy, rapid churn, abnormal resolution patterns and lack of meaningful brand association are often more informative than what a name appears to reference. These properties reflect how domains are used by automated systems, not how a person would interpret them.
Attackers also adapt their domain generation techniques. Methods originally developed for automated infrastructure, including registered and dictionary‑based domain generation, are increasingly used to produce large volumes of human‑plausible names at scale. These domains may appear more natural than traditional algorithmically generated strings, not because a human is absent from the loop, but because a human is expected to be fooled.
This shift highlights the distinguishing constraint of human‑targeted attacks. The success of the domain depends not on resolution alone, but on how the name is read, interpreted and trusted. The way a domain is generated does not determine whether it is system‑targeted or human‑targeted. What matters is whether a human is expected to interpret and trust the name. (Infoblox Research, Registered DGAs: The Prolific New Menace No One Is Talking About).
Human in the Crosshairs
Lookalike and phishing domains operate on entirely different logic. These domains must be seen, recognized and trusted by a real person under normal cognitive load. A phishing email targeting bank customers must produce a domain that, on a quick glance in a mobile browser, looks like it belongs to that bank. A credential-harvesting page impersonating a corporate VPN login must feel familiar enough that an employee entering their password does not pause to question it.
The attack is not optimizing for technical evasion. It is optimizing for believability.
This makes the design constraints entirely different. The attacker must choose a name that is registerable, memorable, plausible and just different enough from the real thing to be unique. Too obvious a fake fails immediately. Too far from the original and it loses its persuasive power. The narrow band in between is where lookalike domains live.
Where Automation Fails
These two classes of attacks place fundamentally different demands on detection. For system‑targeted domains, statistical and behavioral analysis is effective because the domain name itself carries little meaning. High lexical entropy, lack of recognizable structure and unusual resolution patterns are strong indicators of automated activity.
The primary signal lies in how domains are used, rather than in what they appear to represent.
When a human reader is involved, this changes the nature of that signal. The domain must be seen, interpreted and trusted by a person at a glance. Importance shifts from statistical properties to semantic plausibility. The domain name is no longer an arbitrary label, but a crafted message intended to be understood quickly and with minimal scrutiny.
This difference limits the effectiveness of purely statistical approaches. A carefully constructed lookalike domain, whether crafted manually or generated at scale, can exhibit entirely normal characteristics by statistical measures. It may have a plausible name, consistent structure and expected resolution patterns. At the same time, many legitimate services, including content delivery networks (CDNs) and third‑party providers, produce domain patterns that deviate from simple expectations. Treating every deviation as suspicious would lead to unacceptable levels of false positives.
These limitations persist regardless of how domains are generated. Automated techniques, including registered or dictionary‑based domain generation, can produce large volumes of human‑plausible names. This does not make the problem more amenable to statistical detection. It reinforces that, for human‑targeted attacks, the relevant signal is semantic and contextual rather than structural.
Lookalike and brand‑referential domains therefore belong squarely in the human‑targeted class. The challenge is not identifying unusual strings but interpreting what a familiar‑looking name is meant to communicate, and to whom.
DNS as Early Signal
There is a second, less obvious implication. Human-targeted attacks must embed their targeting intent into the domain name itself, because the name is what the victim sees. An attacker who wants to harvest PayPal credentials cannot use a random-looking string. The domain has to reference PayPal in some recognizable way. This constraint, imposed by the need to deceive humans, is exactly what makes these domains visible in DNS traffic.
The targeting is structural. It is written directly into the name. And it remains observable long before and long after any malicious activity occurs.
3. Anatomy of a Lookalike
Lookalike attacks do not have a single form. They span several dimensions of manipulation, including character‑level tricks, keyword association and structural deception. All of them exploit the same underlying vulnerability: the way humans read and recognize domain names. Figure 2 shows several common dimensions of lookalike attacks. While not exhaustive, it highlights how different techniques exploit the same underlying cognitive shortcuts.
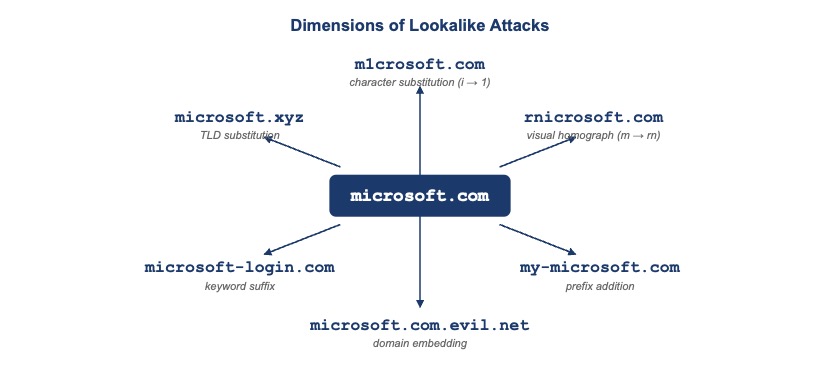
Figure 2. Dimensions of lookalike attacks: one target, many variants
For any popular brand, attackers may use many viable approaches and combinations of tricks: a homograph embedded in a subdomain, a keyword suffix on a visually substituted name, a typosquat or a real domain name with an alternate top-level domain (TLD). The choice of technique depends on the intended delivery channel, the target audience and the level of scrutiny expected. A phishing email to unsophisticated users might use a simple keyword suffix; a spear-phishing campaign targeting security-aware employees might use a carefully crafted homograph. The common thread is the attacker’s model of the victim’s perception, not the technical construction of the name.
That perception operates on predictable principles.
Perception as the Attack Surface
The brain does not read text the way a parser does. Consider this well-known demonstration:
Aoccdrnig to rscheearch, the huamn biran deos not raed ervey lteter by istlef, but the wrod as a wlohe.
Most readers process that sentence without difficulty. The brain autocorrects. It matches the overall shape and context of a word against familiar patterns and fills in the rest. This is not a flaw; it is an essential cognitive efficiency that allows fluent reading at normal speed.
Attackers exploit exactly this mechanism when crafting domain names. A person glancing at paypa1.com or arnazon.com in a browser bar, in a moment of normal inattention, often resolves the visual discrepancy automatically before consciously registering it. The brain saw what it expected to see.
Domain names compound this vulnerability in two ways. First, attention is front-loaded: the beginning of a string receives the most scrutiny, and focus dissipates toward the end. Figure 3 illustrates this left‑to‑right decay in attention when people read domain names. Second, most people have no trained expectation of what a domain name “should” look like beyond the brand label—so the surrounding structure (the TLD, the subdomain path) is processed with even less care. A name that feels right is accepted as right.

Figure 3. Left-to-right attention decay in domain names
Attackers exploit this systematically. One of the particularly popular patterns is domain embedding, shown in Figure 4, where a trusted brand is placed early in a longer fully qualified domain name and interpreted before the actual registrable domain.

Figure 4. Anatomy of an embedded-domain lookalike
Consider:
login.paypal.com.secure-verification.net
A parser reads this right-to-left. The actual domain is secure-verification.net. A human reads left-to-right and sees login.paypal.com as a completely legitimate‑looking subdomain path, long before their attention reaches the part that matters.
Generalizing the pattern:
[prefix] . <embedded-domain> . [suffix] . <imposter-domain>
The prefix and suffix are optional labels added to reinforce the deception (“login”, “secure”, “verify”, “support”). The <embedded-domain> is the trusted brand being impersonated, possibly including its TLD. The <imposter-domain> is where the attacker actually controls resolution.
It is worth noting that the mechanics of domain embedding, including how legitimate services use this pattern and how it can be abused to conceal malicious activity inside trusted infrastructure, are explored in depth in a separate post: Hiding in Plain Sight: Abusing Composite Domain Names. In that context, an attacker misuses an existing service, such as a translation proxy or an email gateway, to route victims through infrastructure that already carries trust.
The situation here is different. The attacker registers the imposter domain themselves. The embedded brand serves purely as a lure for the human reader, while the DNS mechanics play only an incidental role.
This distinction has a practical consequence. An attacker who sets up a wildcard DNS record on their imposter domain (*.secure-verification.net) gets every possible brand-referencing subdomain for free. login.paypal.com.secure-verification.net, vpn.company.com.secure-verification.net and others. None of these need to be configured individually. The attacker creates one domain; the wildcard does the rest. Each variation is a one-off, never-before-seen query in DNS—appearing as an isolated event with no prior history—yet all share the same structural intent.
Variations on the Same Cognitive Exploit
Domain embedding is one pattern, but the same underlying idea appears across several other forms. In each case, the attacker designs the domain to align with how people read, type, and interpret names under normal attention constraints, not with how systems parse them.
- Homographs and Visual Substitutions: Visually misleading domains like paypa1.com, g00gle.com and arnazon.com replace characters with visually similar alternatives. Typical substitutions include 1 for l, 0 for o, vv for w and rn for m. When viewed quickly, especially on mobile devices, the reader often resolves these differences automatically. The name is perceived as the intended brand rather than examined character by character.
- Typosquatting: Common misspellings appear in domains such as amazom.com and gooogle.com, which fall within the range of typing errors users routinely make under time pressure. Because the result still looks plausible, users often proceed without noticing the mistake. This targets motor habits and inattention rather than visual similarity.
- Keyword‑Adjacent Domains: Examples include paypal-blocked-account.com and facebook-activate-account.com, where a recognizable brand is combined with urgency‑laden terms like blocked, verify or activate. The domain itself is easy to read and technically correct, but the language is chosen to trigger action before careful scrutiny occurs.
- Topic‑Cluster Domains: Coordinated sets of thematically related domains are used together, for example home-security-services.com and home-protection-services.com. Each domain appears individually legitimate, but taken collectively they reveal deliberate targeting of a specific concern. This exploits contextual trust built through repetition rather than deception within a single name.
All of these succeed for the same reason: They are calibrated for human cognitive shortcuts, not technical analysis. A security system that checks for exact matches misses all of them.
Impersonation vs. Acting on Behalf
Not every lookalike domain claims to be the target brand. Some claim merely to act on its behalf, for example, as an authorized service, a partner or a support channel. This distinction matters because the two approaches carry different social signals and create different detection challenges.
Direct impersonation aims to convince the victim that they are interacting with the real organization. The domain is constructed to disappear into familiarity. Acting-on-behalf domains take a softer approach. They do not deny being a third party, but they imply a relationship that grants them legitimacy. A domain like paypal-support-services.com or microsoft-partner-login.com never explicitly claims to be the real thing, yet it benefits from the brand’s authority by association.
DNS alone cannot reliably distinguish between these two strategies. Both produce structurally similar domain names. Both reference the same target brands. The difference lies in the intended victim’s interpretation, which is invisible in DNS data. This is one reason detection must be treated as risk discovery rather than verdict rendering.
4. Choosing the Target: Social Groups and Brand Selection
Attackers do not start by choosing a trick. They start by choosing an audience. In lookalike attacks, the brand or domain name is selected not because it looks convincing in the abstract, but because it anchors trust for a particular social group. PayPal users, customers of a local bank, employees of a specific company or users of a government service all carry different expectations and habits. The lookalike domain communicates a simple message: This is for you.
For that reason, brand choice is an expression of social intent. Frequently impersonated brands are rarely accidental. They correspond to populations that are large, reachable and easy to identify. A global payment service offers an enormous pool of plausible targets. Yet some of the most damaging attacks aim at far smaller groups. A campaign focused on a finance department may impersonate an internal accounting system or a familiar vendor portal. Outside the organization, the domain appears unremarkable. Inside, it carries immediate meaning and authority.
Taken together, these cases form a continuum. Some lookalike attacks are optimized for scale, with minimal effort applied across many victims. Others are optimized for precision, with significant effort concentrated on a handful of high‑value individuals. Across this entire range, the constant is the role of the domain name as a signal of trust to the intended audience. Because that signal is encoded in the name itself, it is visible in DNS regardless of scope.
This distinction matters operationally. The risk posed by a lookalike domain does not increase with traffic volume. A single query directed at a single executive can outweigh thousands of hits from a generic phishing campaign.
5. The Attacker Dilemma
Lookalike attacks are shaped by a set of deliberate tradeoffs. Understanding these tradeoffs explains patterns that might otherwise appear accidental or inconsistent.
Plausibility Requires Restraint
A domain that looks obviously fake fails immediately. Attackers introduce the smallest deviation necessary to register a unique name while remaining convincing. Minor differences are subconsciously normalized by victims, especially under time pressure or limited attention.
Takedown Risk Shapes Uptime Strategy
Phishing infrastructure typically has a short active lifetime, often measured in tens of hours. Figure 5 illustrates a common lifecycle, where domains alternate between parked states and short active campaign windows before being reused. Attackers compensate by leaving domains dormant or pointed at benign content during preparation and cooldown periods, often referred to as “aging” the domains. Malicious destinations are used only during active campaigns, reducing exposure and delaying enforcement.
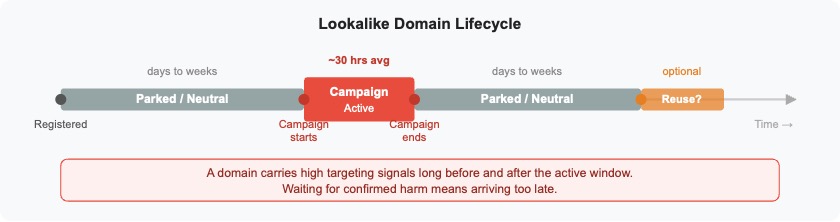
Figure 5. Lookalike domain lifecycle: parked → active campaign → parked → reuse
Infrastructure Is Reused for Efficiency
The same imposter domain may embed different target brands over time or support multiple campaigns across regions. Ownership and intent are fluid rather than fixed. What matters operationally is current use, not the static existence of the domain.
Ambiguity Is Intentional
A domain that could plausibly belong to a legitimate CDN, a reseller service or a benign third‑party provider is far harder to block than one that is clearly malicious. Maintaining uncertainty slows classification and response, extending operational lifetime. Attackers design for deniability on purpose.
This final point has direct consequences for detection. Systems that wait for certainty before acting will always lag behind. Effective defense in this space is about risk discovery and prioritization, not binary verdicts.
Ambiguity is not a bug in lookalike attacks. It is the feature that keeps them alive.
6. DNS as a Sensor of Social Intent
Passive DNS, the record of domain resolution requests and responses observed above the resolver, provides a powerful signal for understanding lookalike attacks. Its value lies in early visibility into attacker intent, but its limitations must be understood and respected.
What DNS Reveals
- Naming Strategy: Structural patterns used in domain construction, including embedded domains, prefix and suffix decoration and homographs
- Brand Targeting: Which legitimate organizations are referenced in domain names and how frequently those references appear across campaigns
- Infrastructure Relationships: Imposter domains that share hosting, reuse structural patterns or repeatedly appear alongside known malicious infrastructure
- Temporal Behavior: How domains appear, go idle and resurface over time; short‑lived, intermittent activity is behaviorally distinct from stable infrastructure
Aggregation is essential. A single suspicious domain is ambiguous. Multiple domains embedding the same brand, deployed by related infrastructure and observed across time, form a meaningful signal.
What Domain Names Alone Cannot Reveal
- Definitive Malicious Intent: A domain embedding paypal.com may belong to PayPal’s own CDN, a legitimate third‑party service, a cybersquatter or a phishing campaign. DNS alone cannot distinguish these cases.
- User Impact: DNS records a resolution request, not whether a user clicked, was deceived or suffered loss.
- Complete Campaign Scope: Without corroborating telemetry, DNS cannot reconstruct the full path, reach or impact of an attack.
These limitations are not weaknesses to apologize for. They are what make DNS analysis credible. DNS offers early, structural visibility into social targeting intent, not post‑hoc attribution or proof of harm.
7. Targets and Imposters: A Dual-Role Model
Thinking clearly about lookalike domains requires separating two roles that are often conflated. Figure 6 presents a dual‑role model that separates targets from imposters, clarifying how trust signaling and delivery infrastructure operate independently.

Figure 6. Targets and imposters: a dual-role model
A target is a domain, brand or naming construct that serves as a trust anchor for a specific social group the attacker intends to reach. In most cases, this is a legitimate and well‑known service such as PayPal, Facebook, a regional bank or a corporate IT portal, because these names carry pre‑existing trust with their users. However, legitimacy is not a defining property. A target can also be a grey‑area service, a shady platform or even a domain intentionally created or monitored by security teams for research, measurement or infiltration purposes.
What defines the target role is not innocence or intent, but recognizability. The target is the reference point that tells the recipient, “this is relevant to you.” A target says nothing about whether the referenced domain itself is malicious. It reflects visibility, familiarity and social meaning, not morality.
An imposter is the domain that operationalizes the deception. It is the entity that ultimately resolves the interaction, whether by hosting content, proxying requests or routing traffic, and it is where control over the user experience resides. In many cases, imposter domains are registered and operated directly by attackers. In other cases, they may consist of legitimate services, shared platforms or intermediary infrastructure that is temporarily abused, misconfigured or intentionally repurposed.
As with targets, impostership is not a permanent property of a domain. A domain’s role as an imposter is defined by how it is used in a given context and at a given time. The same infrastructure may function as an imposter in one campaign and play a neutral or even defensive role in another.
Together, targets and imposters describe a relationship, not a moral classification. One expresses who the message is meant for, the other determines where the interaction resolves.
This framing has practical value. It separates the question of who is being attacked (target) from imposter attribution, and it acknowledges that neither role is a permanent verdict.
Example: When Imposters and Targets Overlap
In practice, the same domain can act as both an imposter and a target, depending on context. Large infrastructure providers such as cloudflare.net, googleusercontent.com or GitHub‑hosted domains routinely embed vast numbers of customer‑controlled subdomains. Some of these subdomains are known to host malicious content, phishing pages or malware distribution sites, making the parent domain functionally equivalent to an imposter in specific events. At the same time, these platforms are themselves frequent targets of impersonation, as attackers craft lookalike domains that reference Cloudflare, Google or GitHub services to exploit the trust users place in those ecosystems.
This overlap does not indicate malicious intent on the part of the platform. It illustrates the core principle of the dual‑role model: impostership and targethood are contextual relationships, not intrinsic properties. A domain can serve as a delivery point for abuse in one situation, a trust anchor for a user population in another and a neutral infrastructure component the rest of the time. Treating these roles as fixed labels rather than situational roles leads to misclassification and brittle detection decisions.
The Benign Overlap Problem
Many legitimate services use structurally similar patterns:
- CDNs and ad networks embed client domains in their fully qualified domain names (FQDNs).
- Third-party analytics and survey platforms reference brand domains in query strings.
- Wildcard DNS configurations and sinkholes produce patterns that resemble embedding.
A detection approach that ignores this overlap will generate so much noise that the signal may become unusable. Modeling the service landscape, including known CDNs, wildcard resolvers and established third‑party patterns, is therefore as important as modeling attacker behavior.
8. Brand Protection vs. Internal Security: Same Detection, Different Response
Lookalike domain detections serve two distinct organizational interests that are often handled by separate teams. Although these functions are typically treated independently, they rely on the same underlying detection signals and fail in predictable ways when detection and response are not deliberately separated.
Brand protection focuses on domains that impersonate an organization to the outside world, targeting customers, partners or public reputation. The immediate risk is borne by individual users who fall for the deception, such as through account compromise or fraud. Consequences for the organization are typically indirect, emerging as reputational, legal or regulatory exposure over time. Responses rely on monitoring, abuse reporting and takedown requests coordinated with registrars, hosting providers and legal teams.
Internal security focuses on domains targeting an organization’s own employees, such as fake VPN portals or spoofed IT help desk pages. The risk is direct compromise. Because the organization controls the environment, responses can be immediate and technical, including blocking, authentication enforcement, containment and incident response.
The DNS detection logic in both cases is the same. The same structural patterns, brand‑embedding techniques and temporal signals apply regardless of whether the intended victim is a customer or an employee. What differs is not how the domain is identified, but what the organization does after identification.
Brand impersonation puts individual users at risk, with harm localized to those who engage with the deception. There is no effective way to directly protect users beyond warning, monitoring and often slow takedown processes. Internal impersonation is fundamentally different. A single successful deception can lead to systemic compromise affecting employees, infrastructure, partners and downstream customers.
Effective programs account for this asymmetry. Detection is shared and centralized, because the signal is the same. Response is separate, explicitly owned and calibrated to the actual risk surface. Treating brand protection and internal security as interchangeable response problems either creates unnecessary disruption or leaves high‑impact attacks unchecked.
9. What a Domain and DNS Signals Can and Cannot Tell Us
Domain names and DNS‑adjacent data provide early structural signals about how an attack is designed and who it is intended to influence. Naming patterns, brand references, delegation behavior, hosting relationships and temporal activity all support inference about targeting and intent, often before any overtly malicious activity occurs.
At the same time, these signals are inherently limited. A domain name alone cannot definitively establish malicious intent. Many legitimate services exhibit patterns that resemble those used by attackers, and human‑targeted lookalike domains are explicitly designed to remain plausible within this ambiguity.
Additional context from related data sources, such as registrar behavior, certificate usage, hosting history and infrastructure relationships, can increase confidence, but it does not remove uncertainty. For lookalike attacks that rely on human interpretation, ambiguity is not a failure of analysis. It is a fundamental property of the attack.
Domain‑based analysis is most effective when used to surface risk and intent rather than to render final verdicts. It supports prioritization, investigation and informed response, but it cannot replace judgment or eliminate ambiguity by design.
Lookalike attacks scale because human cognition scales. Every new brand, every new user population and every new communication channel expands the attack surface, not due to technological change, but because the pool of trusted targets grows. DNS offers a persistent, structural view into how that targeting is expressed. Its value lies in being used honestly, with responses designed for ambiguity rather than certainty.
Lookalike attacks are difficult to address not because the signals are weak, but because the ambiguity is intentional. What matters is not simply whether a domain is valid or invalid, but what it is designed to communicate and to whom.


